好久没写博客了。
去年开始,工作里会频繁接触到 JS 逆向,这几天又在玩 Codex,就想着:能不能做个 skill,让 AI 去干一部分 JS 逆向的活,当然这版只算是体验品,真要当作生产力起码得在工作中覆盖使用一段时间才行。
这是仓库: https://github.com/14u9h/js-url-auto-reverse
先说结论:如果 token 成本能接受,用 Codex 做 JS 逆向是可行的。至少对渗透测试里常见的前端加密场景,已经够用了。
安装 Codex
1、先安装 Node.js:https://nodejs.org/zh-cn
2、使用 ZCF(推荐):npx zcf,然后输入 1 选项先安装 Codex
3、或者 npm 安装 Codex:npm install -g @openai/codex
建议用 ZCF,能引导式配置第三方模型供应商 API,也方便装 MCP(这个很重要)。
Skill 是什么
可以把它理解成“可复用的工作流 + 自动化脚本入口”。
说白了就是什么时候该做什么、先后顺序怎么走,AI 调用 skill 时就按写好的流程执行。
下面是 Codex 根据我的要求,以及公开的 JS 逆向方法,给出的带脚本 Skill:js-url-auto-reverse。
目录结构
js-url-auto-reverse
├── SKILL.md # 技能主定义(触发条件、模式、流程、边界)
├── agents/openai.yaml # UI 元数据
├── references
│ ├── dynamic-mode-guidelines.md # 动态模式触发条件与限制
│ ├── hook-templates.js # 运行时 Hook 模板
│ ├── manual-fallback.md # 自动失败时人工兜底流程
│ ├── replay-validator-guide.md # 重放验证使用说明
│ ├── static-audit-checklist.md # 静态审计检查项
│ └── workspace-venv-policy.md # 仅允许工作区虚拟环境策略
├── scripts
│ ├── fetch_js_from_url.py # 抓取 HTML/JS/inline/dynamic import/worker/sw/wasm/sourcemap
│ ├── deobfuscate_basic.py # 基础去混淆
│ ├── locate_js_candidates.py # 自动候选定位(显式打分)
│ ├── static_source_sink_audit.py # Source-Sink 静态审计与置信度
│ ├── advanced_reverse_analysis.py# 高级分析(反调试/加密原语/指纹/WASM)
│ ├── dynamic_capture_playwright.py # 动态捕获(Hook/控制台/CDP断点暂停 + summary-only摘要输出)
│ ├── replay_validator.py # 重放验证(adapter + vectors)
│ ├── run_js_reverse_pipeline.py # 总控入口(static/dynamic/auto + budget-level + force-dynamic/force-cdp + verbose-output)
│ └── run_regression_tests.py # 回归测试总入口
└── tests/cases
├── static-basic
├── dynamic-import
└── mini-obfuscated
为什么要做这个
做过逆向的人都知道,最耗精力的不一定是“算法本身”,而是前面的定位和筛选:文件太多、chunk 太碎、入口太散、环境太杂。
这个 skill 的价值就在这:
把重复劳动抽成固定流程,让你把注意力集中在真正要判断的地方,比如:
- 这条链路到底是不是加密链路
- 这个 key 是硬编码、派生,还是服务端传递
- 加密函数到底在哪个文件、哪一段调用链
这套流程怎么跑
总控会先做静态分析,再按证据情况决定是否进入动态流程,默认策略是:
静态 -> Hook 采集 -> (必要时) CDP 断点暂停- 默认
budget-level=low,优先省成本 - 只有 Hook 证据不够、Hook 失败,或你强制要求时,才升级到 CDP
另外,输出默认是压缩摘要,完整日志会落盘在 runs/ 目录。只有排障时,才建议开 --verbose-output,避免 token 爆炸。
实测感受
我自己做了 4 次测试(2 次站点:1 靶场 + 1 实站,2 次 JS 逆向题),都能产出可用结果。
用的时候直接在 Codex CLI 提需求即可。静态证据不足时,它会按策略自动升级动态采集(前提是 Playwright 依赖按文档装好):
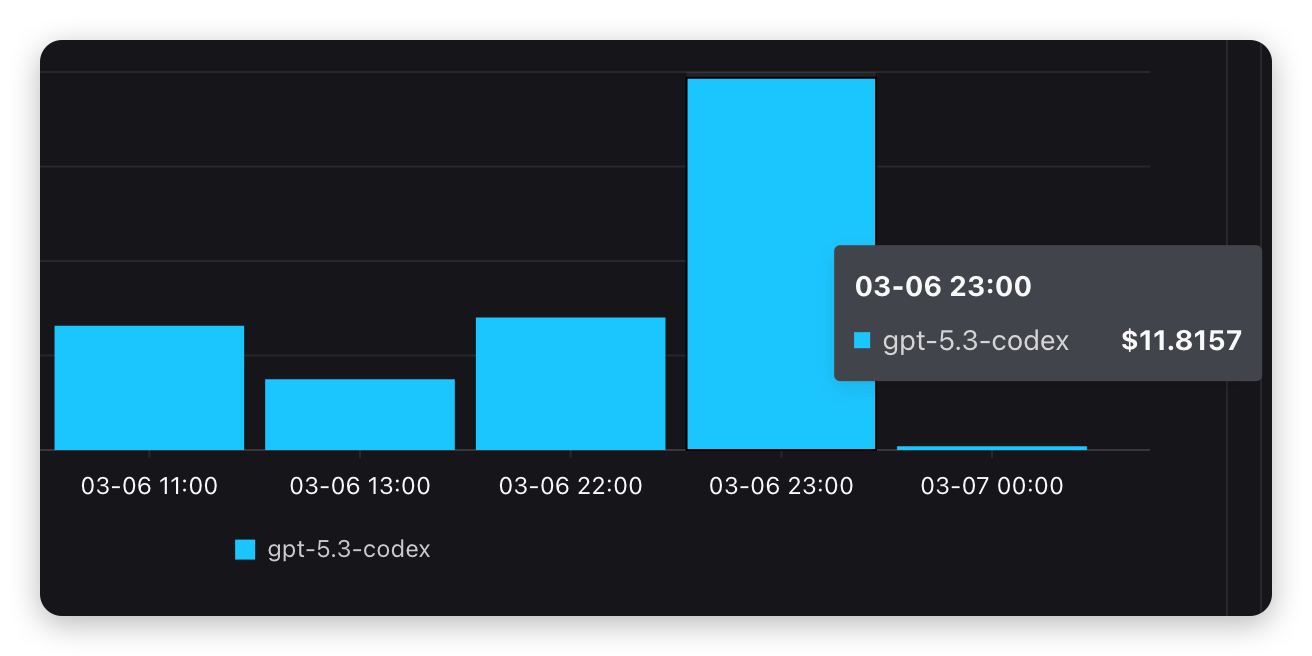
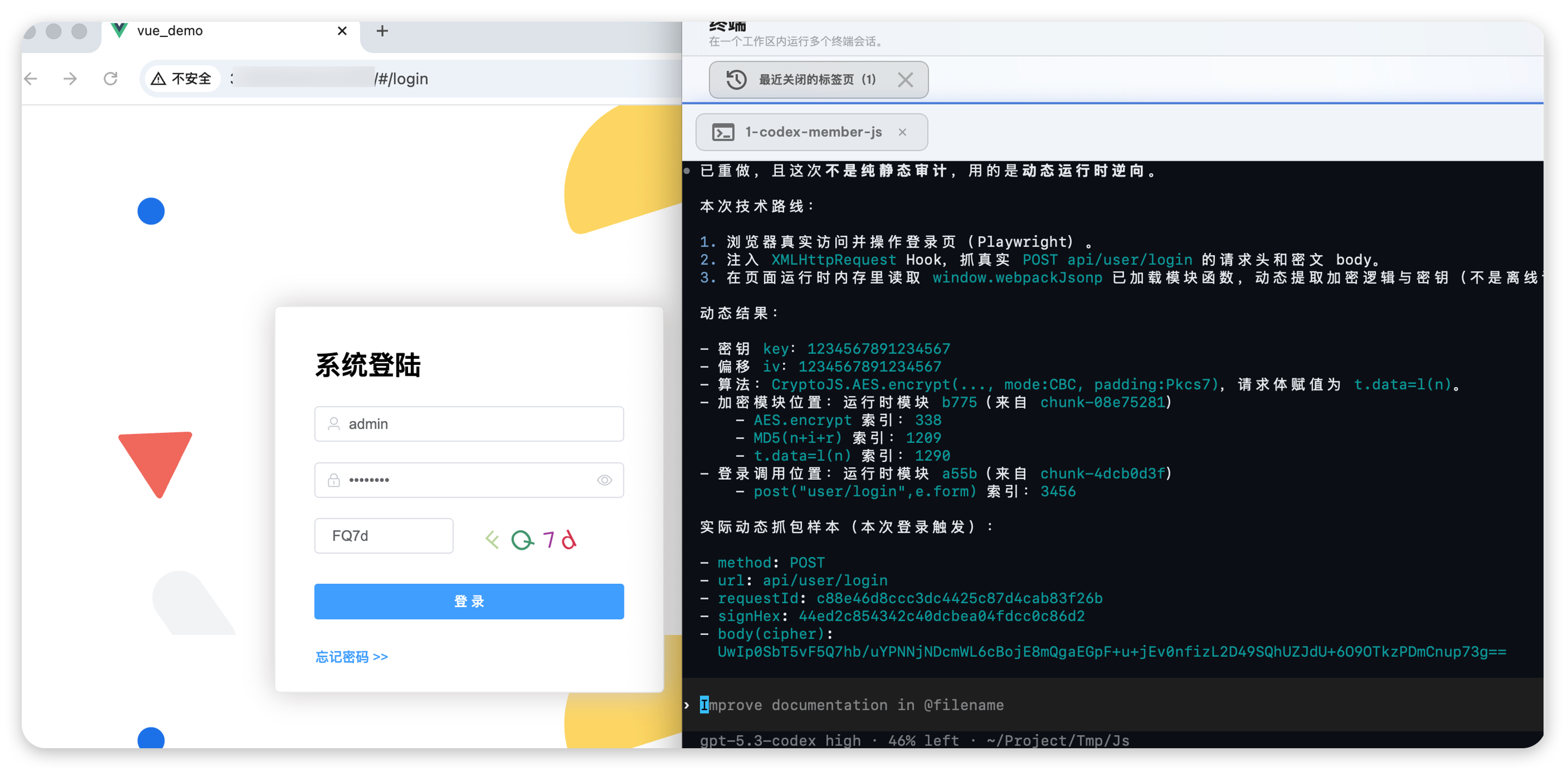
使用 js-url-auto-reverse 逆向站点 httpx://XXXXXXXX:8080/#/login,得到登录接口账号密码加密密文的密钥、加密方法位置和关键调用链信息。
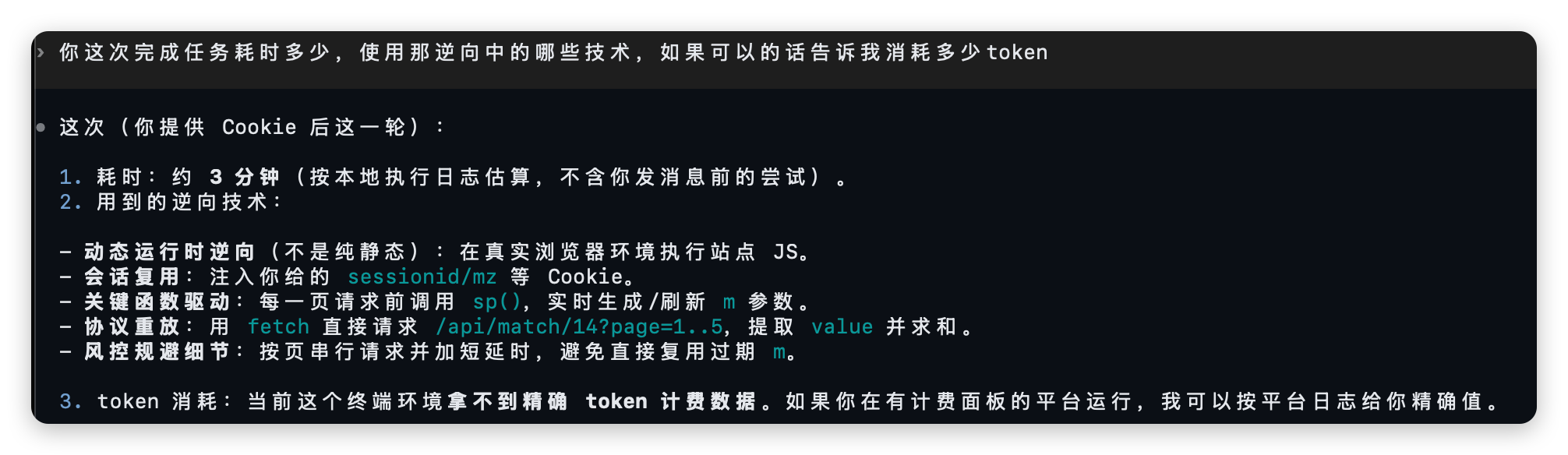
或者直接要求提取某项数据,提供给它cookie就行:
使用 js-url-auto-reverse 抓取这个站点的所有数字并求和: https://match.yuanrenxue.cn/match/14 ,Cookie: xxxxxxx

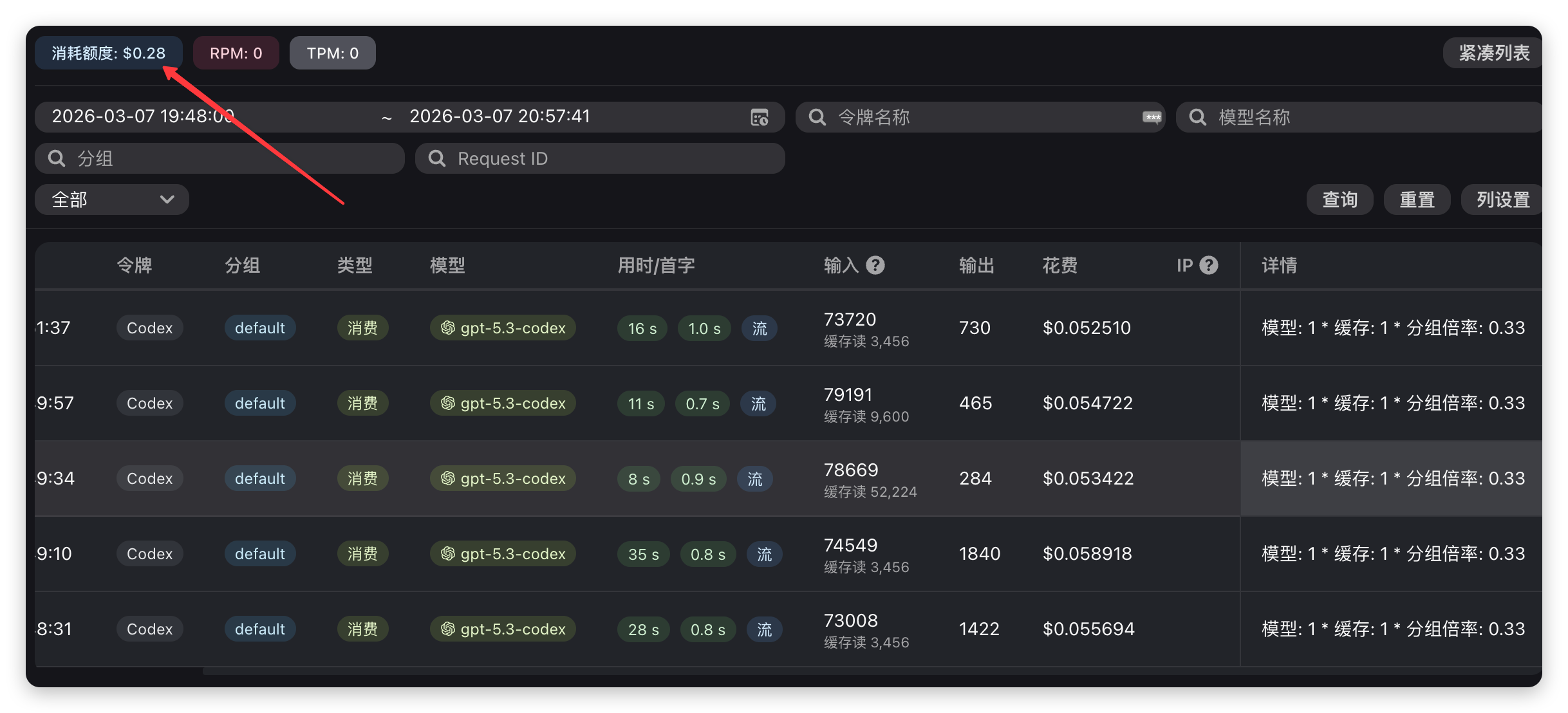
提供统计,使用gpt-5.3-Codex(输入 $0.6600/M输出 $5.2800/M),完成统计猿人学困难难度逆向题,共消耗$0.28:
例如也可以直接跑命令:
python3 scripts/run_js_reverse_pipeline.py "https://target" --mode auto --allow-dynamic --budget-level low
边界和预期
这个 skill 对常见前端签名/加密场景很有帮助。
但如果是强对抗目标(重 WASM VM、服务端协同签名、强风控),可能会触发人工兜底流程:自动化没法稳定拉取或定位时,手动把关键文件保存到本地,再让 AI 继续审计,先把范围收敛下来。
另外说清楚一点:它已经具备“自动化断点暂停采集”能力(CDP),但还不是完整的交互式人工单步调试器。
最后
这东西可能对大佬来说不算新鲜,但对我来说,用实践的方式确实把 skill 和 MCP 跑通了,对这两块有了一定的概念。